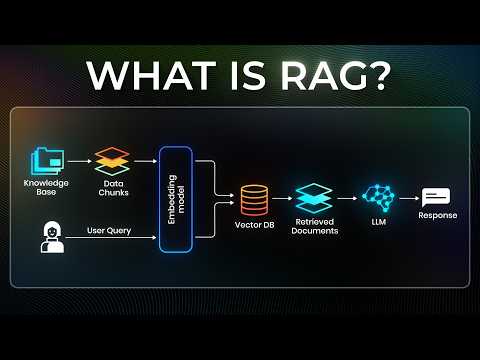
Challenge: Need to connect an AI assistant to 500 GB of documents for efficient querying.
Limitations: Typical chat applications can't handle large file sizes; searching through all documents for each query is inefficient.
Proposed Solution Combine two methods: document summarization and semantic search using vector embeddings.
Convert documents into vector embeddings to store in a database, preserving semantic meaning.
RAG (Retrieval Augmented Generation):
Three Steps Retrieval: Convert user queries into vector embeddings and perform semantic search against document embeddings.
Augmentation: Inject retrieved data into the AI prompt to provide up-to-date information without fine-tuning the model.
Generation: AI generates responses based on the augmented data.
Key Benefits of RAG:
Provides real-time, relevant answers using current data.
Enhances AI's knowledge beyond static pre-training data.
Implementation Considerations Chunking Strategy: Determine size and overlap of document chunks for effective storage and retrieval.
Embedding Strategy: Choose appropriate models for converting documents into vector embeddings.
Retrieval Strategy: Set thresholds for similarity and apply filters for effective data retrieval.
Practical Steps in Implementation:
Set up a development environment (Python, necessary libraries).
Initialize a vector database (e.g., Chroma DB).
Develop a chunking script to preserve context.
Use embedding models to convert documents and queries into vectors.
Store vectors and metadata in the database.
Implement a semantic search engine.
Create a web interface for user interaction.
Testing and Evaluation Conduct tests to ensure all components function correctly.
Evaluate the quality of retrieval and answer helpfulness through tuning.
Final Note: The setup of a RAG system varies based on the dataset, requiring tailored strategies for different types of documents (e.g., legal vs. conversational).
Overview
1Challenge: Need to connect an AI assistant to 500 GB of documents for efficient querying.
2Limitations: Typical chat applications can't handle large file sizes; searching through all documents for each query is inefficient.
3Proposed Solution Combine two methods: document summarization and semantic search using vector embeddings.
4Convert documents into vector embeddings to store in a database, preserving semantic meaning.
5RAG (Retrieval Augmented Generation):
6Three Steps Retrieval: Convert user queries into vector embeddings and perform semantic search against document embeddings.
7Augmentation: Inject retrieved data into the AI prompt to provide up-to-date information without fine-tuning the model.
8Generation: AI generates responses based on the augmented data.
9Key Benefits of RAG:
10Provides real-time, relevant answers using current data.
12Implementation Considerations Chunking Strategy: Determine size and overlap of document chunks for effective storage and retrieval.
13Embedding Strategy: Choose appropriate models for converting documents into vector embeddings.
14Retrieval Strategy: Set thresholds for similarity and apply filters for effective data retrieval.
15Practical Steps in Implementation:
16Set up a development environment (Python, necessary libraries).
17Initialize a vector database (e.g., Chroma DB).
18Develop a chunking script to preserve context.
19Use embedding models to convert documents and queries into vectors.
20Store vectors and metadata in the database.
21Implement a semantic search engine.
22Create a web interface for user interaction.
23Testing and Evaluation Conduct tests to ensure all components function correctly.
24Evaluate the quality of retrieval and answer helpfulness through tuning.
25Final Note: The setup of a RAG system varies based on the dataset, requiring tailored strategies for different types of documents (e.g., legal vs. conversational).
Study Notes
Context: Implementing an AI assistant to answer questions from 500 GB of documents.
Challenge: Traditional chat applications can't handle large file sizes efficiently.
Solution: Use a RAG system to improve document retrieval and response generation.
Word Embedding Human language is converted into numerical representations for processing by computers.
Vector Embedding Documents are stored as vectors that preserve the semantics (meaning) of the words.
Semantic Search A search method that matches the meaning and context of a query against existing documents, rather than relying solely on static keywords.
Retrieval Convert both documents and user queries into vector embeddings.
Compare the query embedding against document embeddings to find relevant content.
Augmentation Inject retrieved data into the AI assistant's prompt at runtime.
Allows the assistant to use up-to-date information from the vector database, enhancing the response quality.
Generation The AI generates a response based on the relevant data retrieved.
Utilizes reasoning to provide accurate answers based on the context of the query.
Chunking Strategy Determine size and overlap of document chunks for effective storage and retrieval.
Example: Size 500 with overlap 100 to preserve context.
Embedding Strategy Choose an embedding model (e.g., MiniLM L6 V2) to convert documents into vector embeddings.
Retrieval Strategy Set thresholds for similarity to filter relevant documents and improve retrieval quality.
Development Environment Set up a Python virtual environment and install necessary packages (e.g., Chroma DB, Sentence Transformers, OpenAI, Flask).
Vector Database Initialization Create a collection for storing document vectors.
Knowledge Ingestion Pipeline Process documents into chunks, embed them, and store vectors with metadata.
Semantic Search Activation Implement a search engine script to fetch top results based on semantic similarity.
Web Interface Create a simple Flask app to allow users to query the AI assistant.
Chunking Different document types (e.g., legal vs. conversational) require tailored chunking strategies.
Model Selection Use compact and effective models for embedding to optimize performance.
Quality Control Implement similarity thresholds to minimize low-quality matches and reduce hallucination in responses.
A RAG system can significantly enhance the ability of an AI assistant to provide accurate, context-aware responses by leveraging a combination of retrieval, augmentation, and generation techniques.
Experimentation with chunking, embedding, and retrieval strategies is crucial for optimizing the system's performance.
Study Notes on Retrieval Augmented Generation (RAG) System
Overview
1Context: Implementing an AI assistant to answer questions from 500 GB of documents.
2Challenge: Traditional chat applications can't handle large file sizes efficiently.
3Solution: Use a RAG system to improve document retrieval and response generation.
Key Concepts
1Word Embedding Human language is converted into numerical representations for processing by computers.
2Vector Embedding Documents are stored as vectors that preserve the semantics (meaning) of the words.
3Semantic Search A search method that matches the meaning and context of a query against existing documents, rather than relying solely on static keywords.
RAG Process Breakdown
1Retrieval Convert both documents and user queries into vector embeddings.
2Compare the query embedding against document embeddings to find relevant content.
3Augmentation Inject retrieved data into the AI assistant's prompt at runtime.
4Allows the assistant to use up-to-date information from the vector database, enhancing the response quality.
5Generation The AI generates a response based on the relevant data retrieved.
6Utilizes reasoning to provide accurate answers based on the context of the query.
Implementation Steps
1Chunking Strategy Determine size and overlap of document chunks for effective storage and retrieval.
2Example: Size 500 with overlap 100 to preserve context.
3Embedding Strategy Choose an embedding model (e.g., MiniLM L6 V2) to convert documents into vector embeddings.
4Retrieval Strategy Set thresholds for similarity to filter relevant documents and improve retrieval quality.
Practical Application
1Development Environment Set up a Python virtual environment and install necessary packages (e.g., Chroma DB, Sentence Transformers, OpenAI, Flask).
2Vector Database Initialization Create a collection for storing document vectors.
3Knowledge Ingestion Pipeline Process documents into chunks, embed them, and store vectors with metadata.
4Semantic Search Activation Implement a search engine script to fetch top results based on semantic similarity.
5Web Interface Create a simple Flask app to allow users to query the AI assistant.
Important Considerations
1Chunking Different document types (e.g., legal vs. conversational) require tailored chunking strategies.
2Model Selection Use compact and effective models for embedding to optimize performance.
3Quality Control Implement similarity thresholds to minimize low-quality matches and reduce hallucination in responses.
Conclusion
1A RAG system can significantly enhance the ability of an AI assistant to provide accurate, context-aware responses by leveraging a combination of retrieval, augmentation, and generation techniques.
2Experimentation with chunking, embedding, and retrieval strategies is crucial for optimizing the system's performance.
Flashcards
Q: What is the challenge faced when connecting an AI assistant to a server with 500 GB of documents? A: Typical chat applications can't accept more than a dozen files, making it inefficient to search through all documents directly.
Q: What is the initial idea to improve the search process for the AI assistant? A: Create an algorithm to search the title and contents of documents to rank them by relevance.
Q: What is the limitation of searching through the entire 500 GB of documents? A: It is a very inefficient way to retrieve information.
Q: What is the proposed method to enhance the search process? A: Pre-process the documents into searchable chunks to improve efficiency.
Q: What is the core idea behind how large language models (LLMs) process input? A: Word embedding, which turns human language into numerical representation.
Q: What is the concept of storing documents in a vector database? A: Preserve the semantics (meaning) of words into vector embeddings for faster retrieval.
Q: What does RAG stand for? A: Retrieval Augmented Generation.
Q: What are the three steps involved in RAG? A: Retrieval, Augmentation, and Generation.
Q: How does the retrieval step work in RAG? A: The question is converted into a vector embedding and compared against document embeddings using semantic search.
Q: What is semantic search? A: A search method that matches the meaning and context of the query against existing documents rather than relying on static keywords.
Q: What is the purpose of the augmentation step in RAG? A: To inject retrieved data into the prompt at runtime, allowing the AI assistant to use up-to-date information.
Q: What is the final step of RAG? A: Generation, where the AI assistant generates a response based on the semantically relevant data retrieved.
Q: What is a critical decision when setting up a RAG system? A: The chunking strategy, which determines the size and overlap of each chunk.
Q: What is the embedding strategy in a RAG system? A: Deciding which embedding model to use to convert documents into vector embeddings.
Q: Why is chunking important in a RAG system? A: It preserves context and improves retrieval quality.
Q: What is the significance of the similarity threshold in a RAG system? A: It helps keep low-quality matches out, reducing hallucination in responses.
Q: What tools were used to set up the development environment for the RAG system? A: Python virtual environment, UV, Chroma DB, Sentence Transformers, OpenAI, and Flask.
Q: What was the chunk size and overlap used in the chunking strategy? A: Chunk size of 500 and overlap of 100.
Q: What does the embedding process involve in the RAG setup? A: Loading a model, encoding sentences, and computing similarities to create vector representations.
Q: What is the purpose of the semantic search engine script? A: To load the collection, embed queries, and fetch top results by semantic similarity.
Q: What is the role of the Flask app in the RAG system? A: To provide a simple web interface for users to ask questions and receive answers.
Q: What is the expected outcome of the RAG system? A: An end-to-end system that is fast, grounded, and extensible, providing accurate answers based on private documents.
Q: What is the challenge faced when connecting an AI assistant to a server with 500 GB of documents?
A: Typical chat applications can't accept more than a dozen files, making it inefficient to search through all documents directly.
Review
Q: What is the initial idea to improve the search process for the AI assistant?
A: Create an algorithm to search the title and contents of documents to rank them by relevance.
Review
Q: What is the limitation of searching through the entire 500 GB of documents?
A: It is a very inefficient way to retrieve information.
Review
Q: What is the proposed method to enhance the search process?
A: Pre-process the documents into searchable chunks to improve efficiency.
Review
Q: What is the core idea behind how large language models (LLMs) process input?
A: Word embedding, which turns human language into numerical representation.
Review
Q: What is the concept of storing documents in a vector database?
A: Preserve the semantics (meaning) of words into vector embeddings for faster retrieval.
Review
Q: What does RAG stand for?
A: Retrieval Augmented Generation.
Review
Q: What are the three steps involved in RAG?
A: Retrieval, Augmentation, and Generation.
Review
Q: How does the retrieval step work in RAG?
A: The question is converted into a vector embedding and compared against document embeddings using semantic search.
Review
Q: What is semantic search?
A: A search method that matches the meaning and context of the query against existing documents rather than relying on static keywords.
Review
Q: What is the purpose of the augmentation step in RAG?
A: To inject retrieved data into the prompt at runtime, allowing the AI assistant to use up-to-date information.
Review
Q: What is the final step of RAG?
A: Generation, where the AI assistant generates a response based on the semantically relevant data retrieved.
Review
Q: What is a critical decision when setting up a RAG system?
A: The chunking strategy, which determines the size and overlap of each chunk.
Review
Q: What is the embedding strategy in a RAG system?
A: Deciding which embedding model to use to convert documents into vector embeddings.
Review
Q: Why is chunking important in a RAG system?
A: It preserves context and improves retrieval quality.
Review
Q: What is the significance of the similarity threshold in a RAG system?
A: It helps keep low-quality matches out, reducing hallucination in responses.
Review
Q: What tools were used to set up the development environment for the RAG system?